In Forward we handle a large real time data stream.
Having already a Hadoop cluster for high latency analysis (mostly reporting), we recently worked on a set of tools that can offer a near real-time view of what’s going on. With this goal in mind I have been recently involved in building a data firehose with NodeJS.
The resulting architecture looks like this:
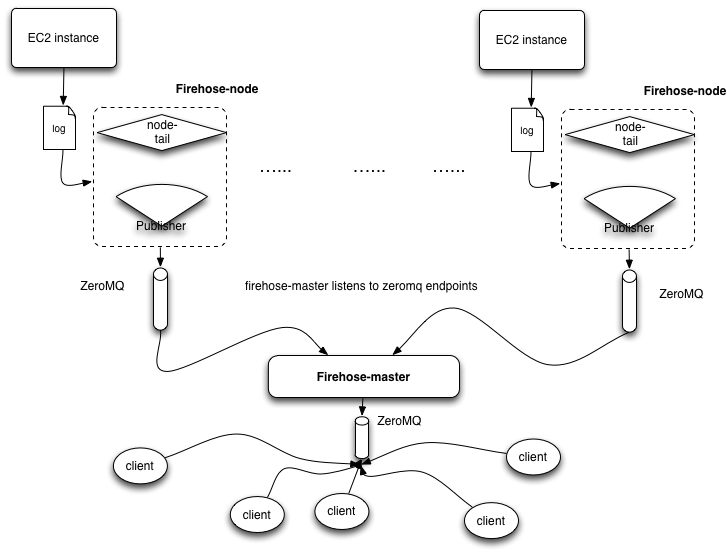
The bottom layer of the firehose is a thin component installed on each server that tails the log file we care about and publishes each log entry to a collector (the firehose-master) via ZeroMQ. The master collects the log entries from all the nodes and republishes everything to the rest of the software ecosystem as a single stream via a ZeroMQ end point.
With this architecture we easily preserve the horizontal scalability of our main service, in fact adding a new node to the firehose is as simple as installing the tail component on the new server and adding its IP address to the master configuration file.
This stream can now act as core foundation for clients systems looking to consume real time data, for example real-time trends visualisation and HDFS data bulk load.