Microservices have received a lot of attention over the last few years. As an architectural style it delivers a lof of benefits compared to a Monolith application, but there’s no doubt that it comes with the cost of a distributed system (such as discoverability, fault tolerance, data consistency just to name a few).
I believe a Microservice architecture shouldn’t be your starting point. Instead, it should be the result of applying Evolutionary Architecture and Domain Driven Design principles to your system, balanced with a analysis of the maturity stage of your product (both from a business and technology perspectives).
While building uSwitch car insurance we followed exactly these principles; since the beginning of the project until today we refined our architecture based on our increased understanding of the business needs, moving from a monolith by choice system to a well defined microservices architecture that keeps evolving and improving.
If I look back at these 3 years I can identify five major stages:
- Fast development cycle
- Support business workflows
- Separation of concerns
- Decouple and scalability
- Leveraging uSwitch technology ecosystem
Stage 1: Fast development cycle
We wanted to build a new product from scratch and we wanted to go live as soon as possible. Our first architecture was optimized to enable us to have a fast development cycle and the shortest path to production.
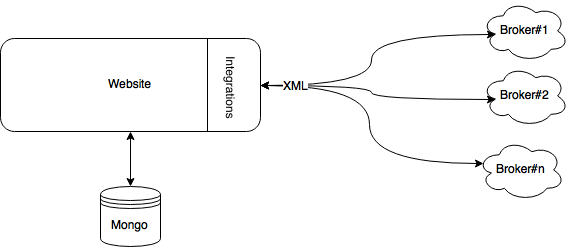
Even if at the beginning of our journey we identified two separate concerns:
- serving the actual website
- integration with multiple insurance APIs for real-time brokerage
Although our experience was already suggesting that Microservices could be an excellent solution for the problems we were going to solve, we wanted a fast development cycle minimum friction between changes and access to production; we also didn’t want to get distracted in building solutions that won’t add much value for our Release 1. We explicitly chose to build a monolith Ruby on Rails application, with a well defined internal boundary between the web code and the integration layer.
Stage 2: Support business workflows
Once the new product went live sales reports from our partners started to flow in (mostly as CSV files over FTP). With sales data we started to identify KPIs and draw correlation between the web traffic, partner offers and the different conversion rates. We knew that the data aggregation and analysis could be done manually for a short time of period, but we had to automate the workflow before the volume was growing. We therefore introduced a new system responsible for sales data ingestion and for producing analytical dashboard.
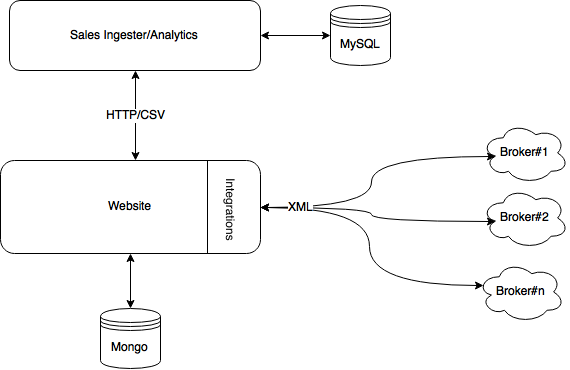
In order to give reliable visits to sales conversion rates the newly built dashboard had to have access to some web-centric data(such as number of unique visitors, number of completed journeys etc etc). We introduced a simple REST APIs on the web layer and use cron jobs to do scheduled data transfer from one system to another. This solution allowed us to move forward, and because it was flawed by choice (data duplication, poor resiliency) it forced us to think over time about what we really need in that space.
Stage 3: Separation of concerns
It was time to move our architecture towards SOA to benefit from much clearly defined bounded contexts.
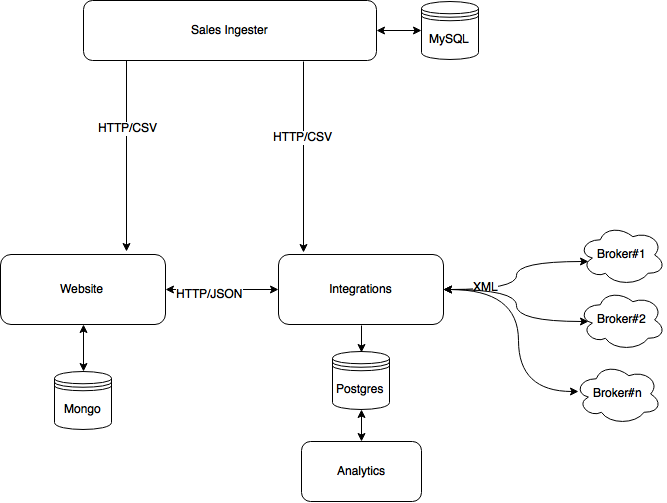
We knew from the very beginning that the integration layer and the websites were two different contexts; while one is responsible to collect and present information the other is responsible to communicate with the external partners and transform data between multiple representations. The integration layer had been encapsulated at the boundary of the web system so far, but it was now time to reify it in an independent service and let it evolve independently from the web. The new service was responsible for pure data transformation: receiving the internal representation of a user profile, transforming it to the different XML flavours expected by the different integrations and transforming the responses back in a normalized representation ready to be used by our website. We felt that the problem space was a good fit for a functional language and we embraced Clojure. The integration between the website and the new aggregation service was HTTP POST with JSON as data type. We also started understanding more of our analytics need: a Postgres instance logically close the Integration layer became our analytics data source.
Stage 4: Decouple and scalability
At this stage we had consistent traffic and sales to really benefit from a more mature data pipeline and analytics platform. REST style integrations brilliantly supported us until this point but we were at a stage where we wanted to increase system resiliency. uSwitch teams have been long time users of Kafka. Kafka is a distributed message system with an eye on message durability. We decoupled the integration layer from the analytics data store(the data transformation was a stateless service by definition anyway) with a set of Kafka topics and few workers. Now the integration layer was just publishing useful information to the topics, enabling multiple consumers to fetch data to support different needs.
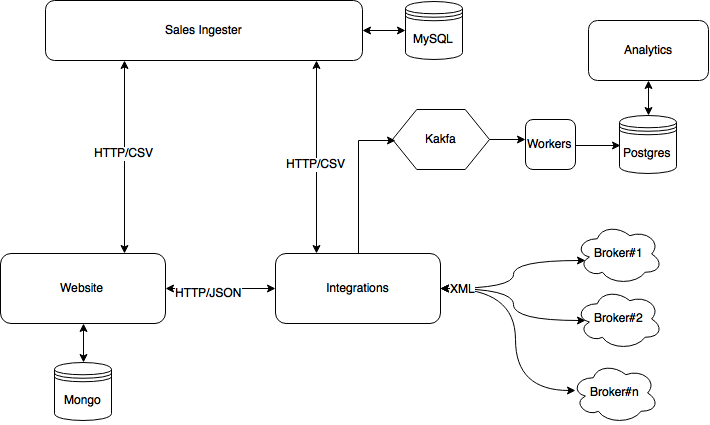
Stage 5: Leveraging uSwitch technology ecosystem
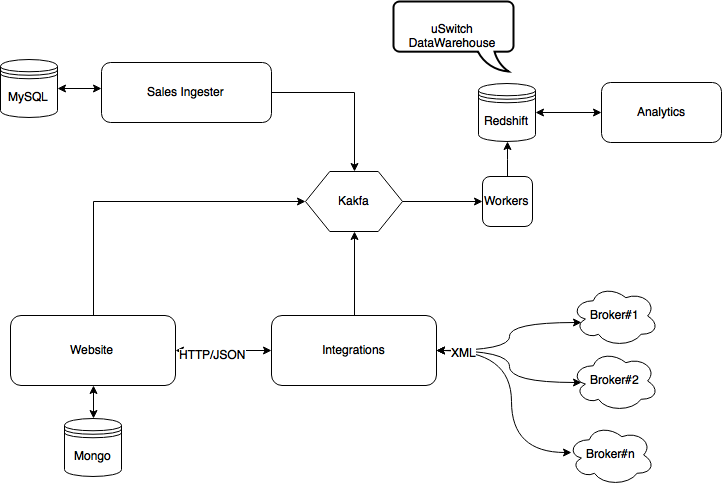
We are now 30 months from the go live and this is our current architecture. The amount of data we produce and collect grew together with our business, and Postgres is not a viable solution anymore. We moved all our long-term analytical data to Redshift, getting us aligned to other uSwitch product teams that were already using it. Redshift now works as cross-channel data warehouse, enabling more in depth analysis and reports than before. We also replaced some of the REST based integrations with more Kafka topics: this gives us better resiliency and the benefit of a set of internal tools build for replayability.